Abstract
Comparing two images in terms of Commonalities and Differences (CaD) is a fundamental human capability that forms the basis of advanced visual reasoning and interpretation.
We develop and contribute a new two-phase approach CaD-VI for collecting synthetic visual instructions, together with an instruction-following dataset CaD-Inst containing 349K image pairs with CaD instructions collected using CaD-VI.
Additionally, we propose an evaluation benchmark with 7.5K open-ended QAs to assess the CaD understanding abilities of LMMs.
Pipeline
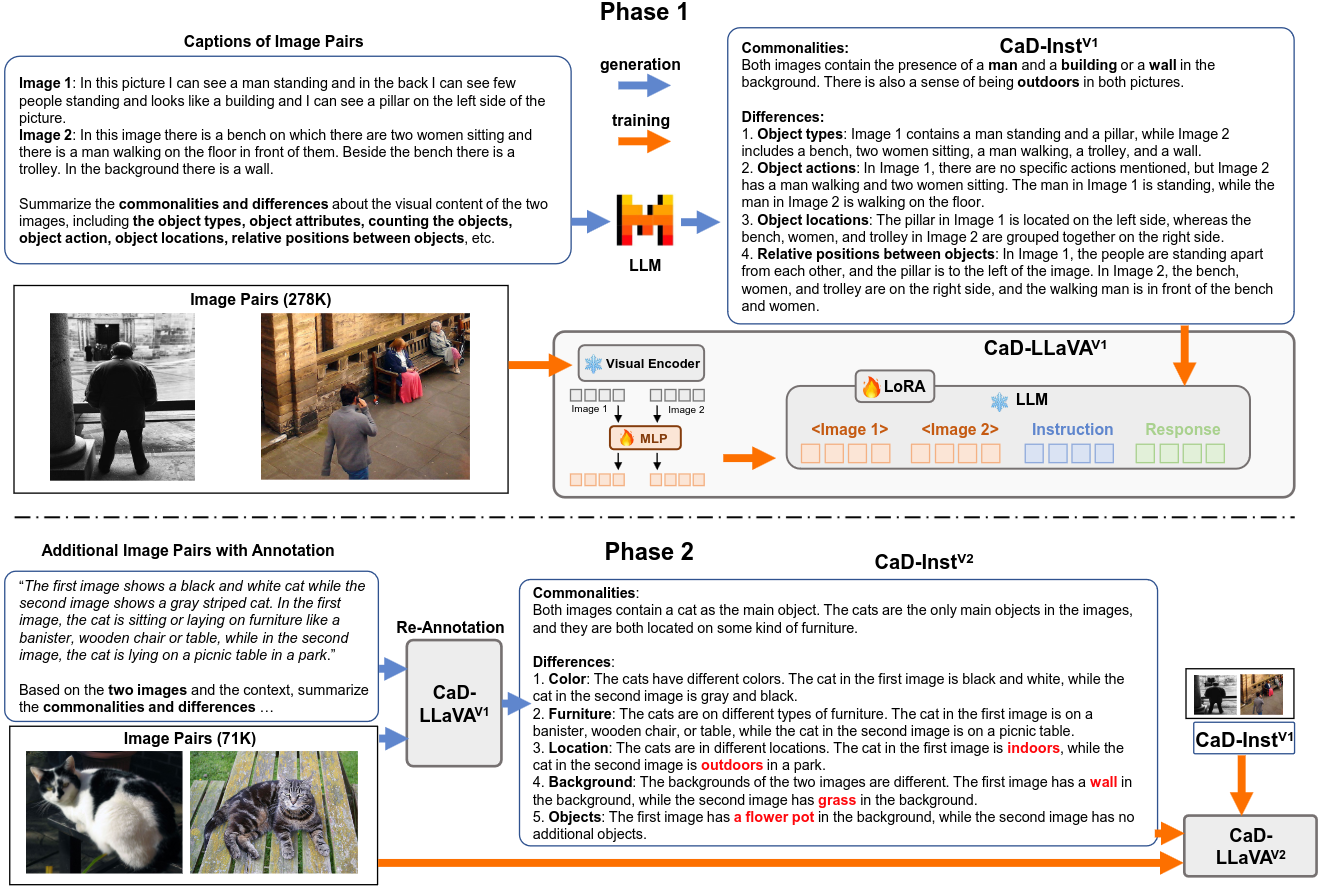
Two-phase data collection: In Phase-1, we leverage captions for image pairs and the Mixtral 8x7B model to generate CaD VI data - CaD-Inst V1 (278K), and perform visual instruction tuning on it to arrive at the Phase-1 model CaD-LLaVA-V1.
In Phase-2, we leverage CaD-LLaVAV 1 to generate CaD VI data on additional image pairs and collect CaD-Inst-V2 (71K). Visual instruction tuning with CaD-InstV 1 and CaD-InstV 2 leads to our final model CaD-LLaVA-V2

Anther example of (a) Phase-1 LLM-collected CaD summary and (b) Phase-2 LMM-collected CaD summary
Data Statistics

Word clouds of CaD summaries in (a) Phase-1 data and (b) Phase-2 data collections
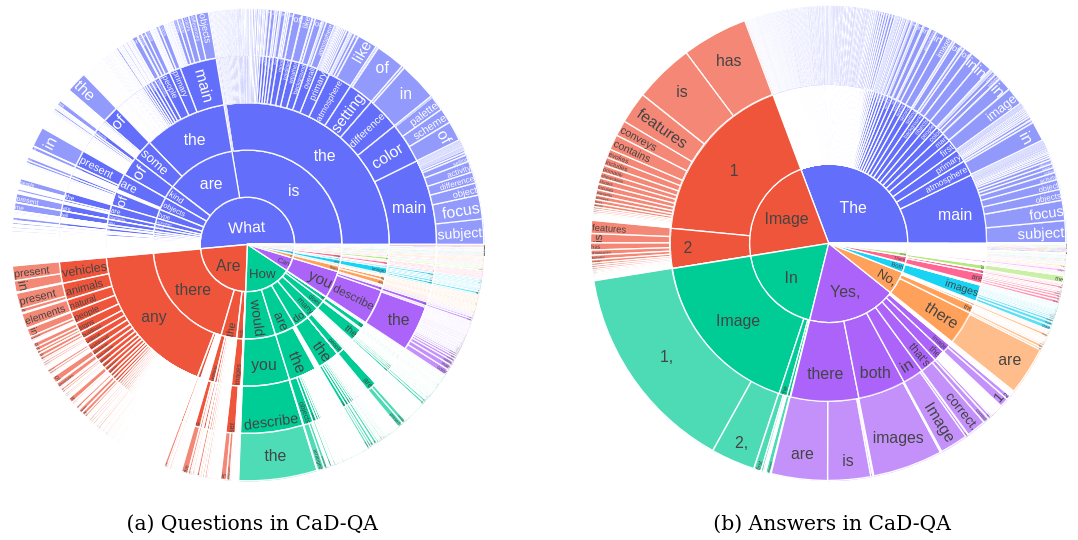
Distribution of (a) questions (first 5 words) and (b) answers (first 3 words) in our collected evaluation benchmark CaD-QA
Examples of Collected QA Pairs


Examples of Q&A pairs in our CaD-QA benchmark together with LMM predicted answers and the corresponding LLM evaluation ratings for the prediction (Red and green texts denote incorrect and correct description).
Reasoning on Binary Image Selection Task

Examples of predictions on binary image selection task (selection of the matched image given a text query). Here we instruct the LMMs to, besides the selection, also give a reasoning for the selection (Red and green texts denote incorrect and correct predictions).