|
I am a research associate at the Institute for Machine Learning headed by Prof. Sepp Hochreiter (Father of LSTM) at the Johannes Kepler University (JKU) Linz. I did my PhD at the Institute of Computer Graphics and Vision, Graz University of Technology (TU Graz ICG) in Austria, supervised by Prof. Horst Bischof (Professor and the Rector of TU Graz) and Prof. Hilde Kuehne (Tuebingen AI Center, University of Tuebingen, MIT-IBM Watson AI Lab) I also work in close collaboration with Leonid Karlinsky and Rogerio Feris (Principal scientists and research manager) from the MIT-IBM Watson AI Lab. Previously, I received my Master's degree in Electrical and Computer Engineering at the Technical University of Munich in Germany. I like traveling 🥾 and learning languages 🌍 I speak English (C1), German (B2), Chinese (mother tongue) and some French. |

|
I am interested in computer vision and machine learning in general. My research is mainly about multimodal large language models, video understanding, reinforcement learning and world models. |
|
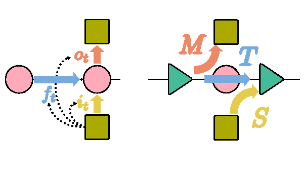
Korbinian Pöppel, Richard Freinschlag, Thomas Schmied, Wei Lin, Sepp Hochreiter, NeurIPS, 2025 arxiv / code / video |
|
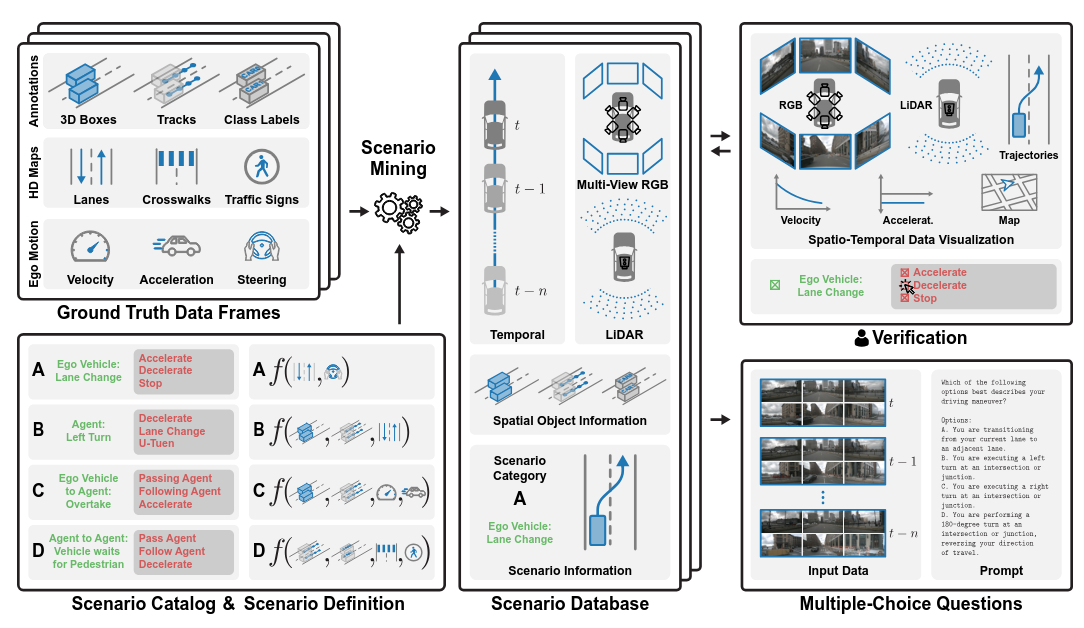
Christian Fruhwirth-Reisinger, Dusan Malic, Wei Lin, David Schinagl, Samuel Schulter, Horst Possegger NeurIPS, 2025 Datasets & Benchmarks Track arxiv / code / video |

|
Paul Gavrikov , Wei Lin, Muhammad Jehanzeb Mirza, Soumya Jahagirdar, Muhammad Huzaifa Sivan Doveh, Serena Yeung-Levy James Glass Hilde Kuehne Arxiv, 2025 arxiv / 🤗 Dataset / code / video |

|
Sivan Doveh, Nimrod Shabtay, Wei Lin, Eli Schwartz, Hilde Kuehne, Raja Giryes, Rogerio Feris, Leonid Karlinsky, James Glass, Assaf Arbelle, Shimon Ullman, Muhammad Jehanzeb Mirza ICCV, 2025 arxiv / code / video |
|
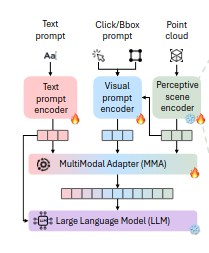
Guofeng Mei, Wei Lin, Luigi Riz, Yujiao Wu, Fabio Poiesi, Yiming Wang CVPR, 2025 arxiv / code / video |
|
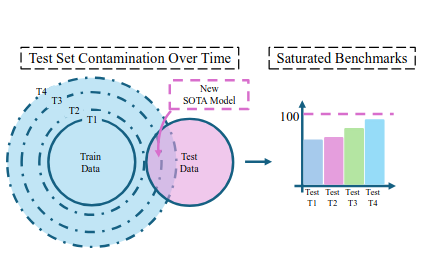
Nimrod Shabtay, Felipe Maia Polo, Sivan Doveh, Wei Lin, Muhammad Jehanzeb Mirza, Leshem Choshen, Mikhail Yurochkin, Yuekai Sun, Assaf Arbelle, Leonid Karlinsky, Raja Giryes ICLR, 2025 arxiv / 🤗 Dataset / code / video |
|
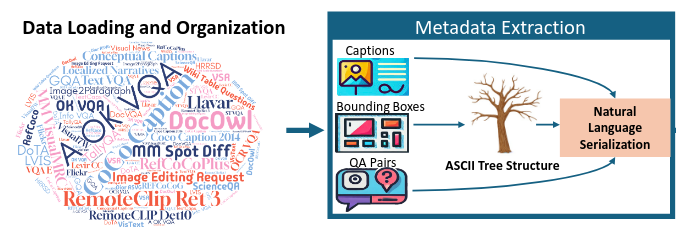
Jacob Hansen, Wei Lin, Junmo Kang, Muhammad Jehanzeb Mirza, Hongyin Luo, Rogerio Feris, Alan Ritter, James Glass, Leonid Karlinsky Arxiv, 2025 arxiv / code / video |
|
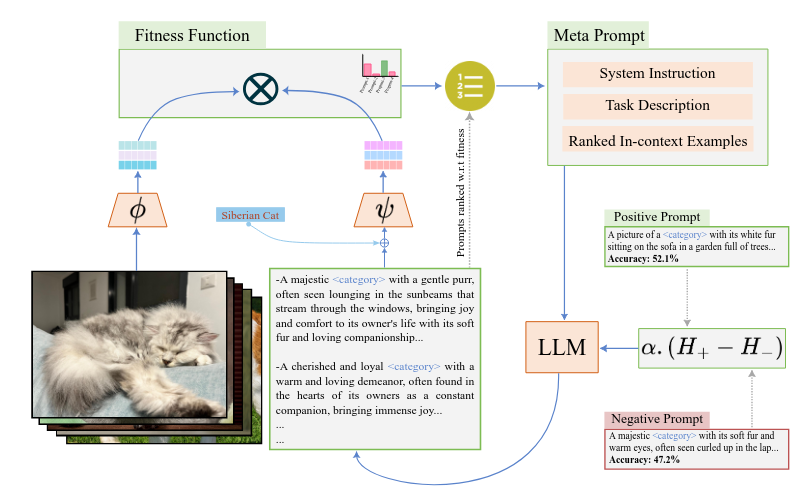
Muhammad Jehanzeb Mirza, Mengjie Zhao, Zhuoyuan Mao, Sivan Doveh, Wei Lin, Paul Gavrikov, Michael Dorkenwald, Shiqi Yang, Saurav Jha, Hiromi Wakaki, Yuki Mitsufuji, Horst Possegger Rogerio Feris, Leonid Karlinsky, James Glass Arxiv, 2024 arxiv / code / video |

|
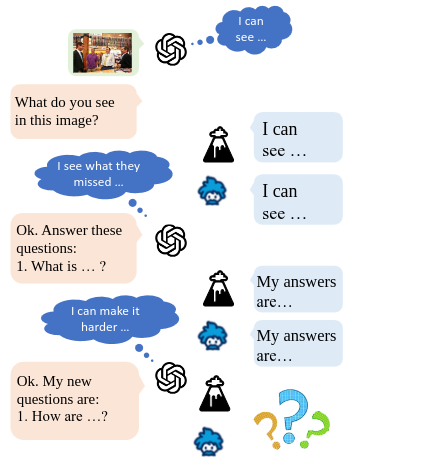
Wei Lin, Muhammad Jehanzeb Mirza, Sivan Doveh, Rogerio Feris, Raja Giryes, Sepp Hochreiter, Leonid Karlinsky In collaboration with the MIT-IBM Watson AI Lab Arxiv, 2024 arxiv / 🤗 Dataset / code / video an approach for collection of visual instructions that improves Commonality and difference spoting capabilities for Large Multimodal Modes |
|
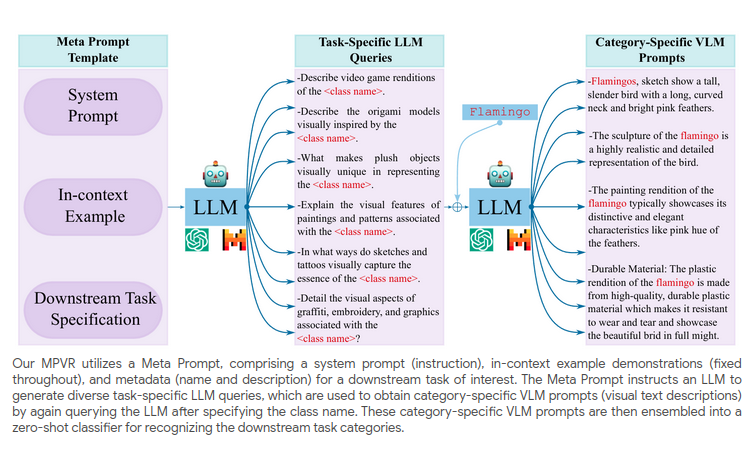
*Irene Huang, *Wei Lin, *Muhammad Jehanzeb Mirza, Jacob Hansen, Sivan Doveh, Victor Ion Butoi, Roei Herzig, Assaf Arbelle, Hilde Kuehne, Trevor Darrell, Chuang Gan, Aude Oliva, Rogerio Feris, Leonid Karlinsky (*equal contribution) In collaboration with the MIT-IBM Watson AI Lab NeurIPS, 2024 Datasets & Benchmarks Track arxiv / 🤗 Dataset / code / video |
|
Muhammad Jehanzeb Mirza, Leonid Karlinsky, Wei Lin, Sivan Doveh, Jakub Micorek, Mateusz Kozinski, Hilde Kuehne, Horst Possegger In collaboration with the MIT-IBM Watson AI Lab ECCV, 2024 arxiv / code / video |
|
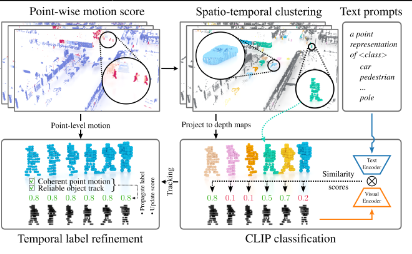
Christian Fruhwirth-Reisinger, Wei Lin, Dusan Malic, Horst Bischof, Horst Possegger BMVC, 2024 Oral Presentation & Best Poster Award arxiv / code / video |
|
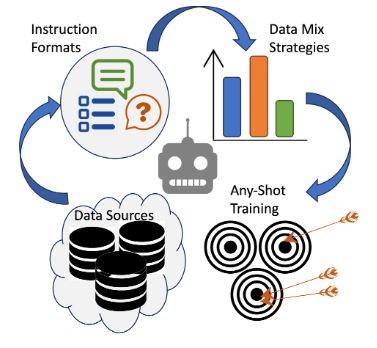
Sivan Doveh, Shaked Perek, Muhammad Jehanzeb Mirza, Wei Lin, Amit Alfassy, Assaf Arbelle, Shimon Ullman, Leonid Karlinsky ECCV 2024 Workshop on Multimodal Agents arxiv / code / video |
|
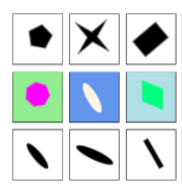
*Bernhard Lehner, *Christian Huber, Bernhard Moser, Claus Hofmann, Wei Lin, Sepp Hochreiter (*equal contribution) Arxiv, 2024 arxiv / code / video |
|
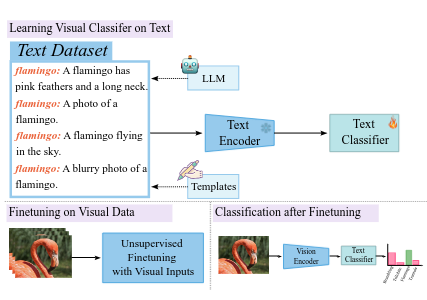
Muhammad Jehanzeb Mirza, Leonid Karlinsky, Wei Lin, Mateusz Kozinski, Horst Possegger, Rogerio Feris, Horst Bischof NeurIPS, 2023 arxiv / code / video |
|
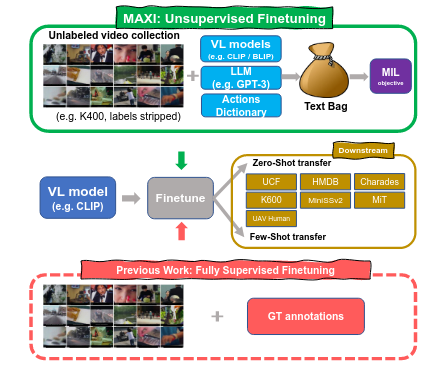
Wei Lin, Leonid Karlinsky, Nina Shvetsova, Horst Possegger, Mateusz Kozinski, Rameswar Panda, Rogerio Feris, Hilde Kuehne, Horst Bischof In collaboration with the MIT-IBM Watson AI Lab ICCV, 2023 arxiv / code / video Unsupervised finetuning of Vision-Language models for zero-shot and few-shot action recognition, with GPT3 text expansion and video frame captioning. |
|
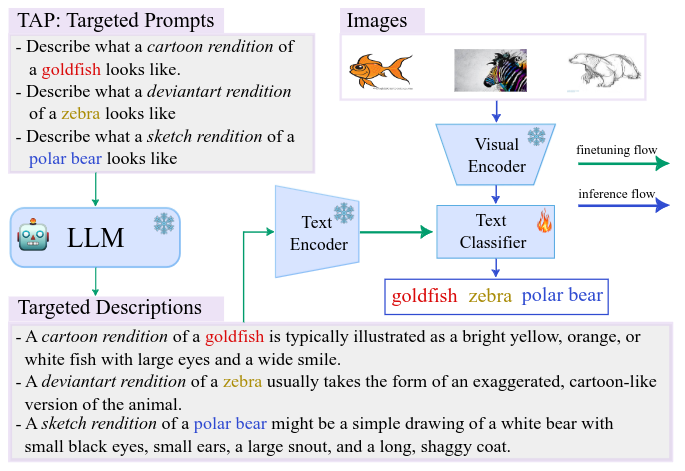
Muhammad Jehanzeb Mirza, Leonid Karlinsky, Wei Lin, Horst Possegger, Rogerio Feris, Horst Bischof Arxiv, 2023 arxiv / code / video |
|
*Muhammad Jehanzeb Mirza, *Inkyu Shin, *Wei Lin, Andreas Schriebl, Kunyang Sun, Jaesung Choe, Horst Possegger, Mateusz Kozinski, In So Kweon, Kun-Jin Yoon, Horst Bischof (*equal contribution) ICCV, 2023 arxiv / code / video |
|
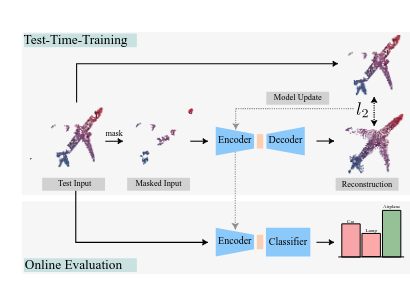
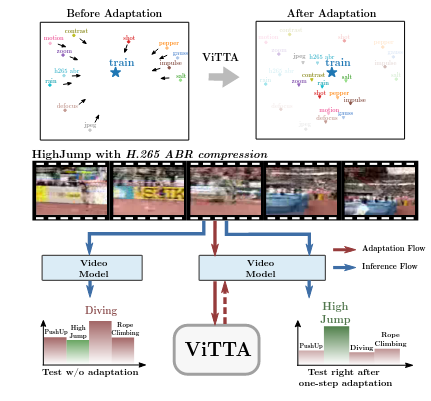
*Wei Lin, *Muhammad Jehanzeb Mirza, Mateusz Kozinski, Horst Possegger, Hilde Kuehne, Horst Bischof (*equal contribution) CVPR, 2023 arxiv / 🤗 Dataset / code / video Test-time adaptation of video action recognition against common distribution shifts. |
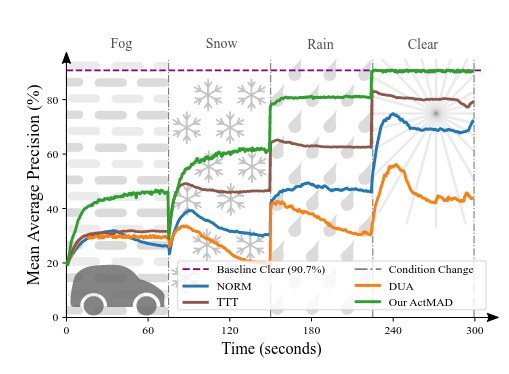
|
Muhammad Jehanzeb Mirza, Pol Jané Soneira, Wei Lin, Mateusz Kozinski, Horst Possegger, Horst Bischof CVPR, 2023 arxiv / code / video |
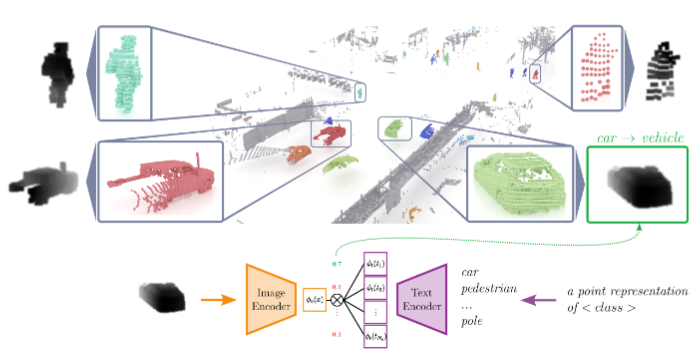
|
Christian Fruhwirth-Reisinger, Wei Lin, Dusan Malic, David Schinagl, Georg Krispel, Horst Possegger, Horst Bischof Arxiv, 2023 arxiv / code / video |
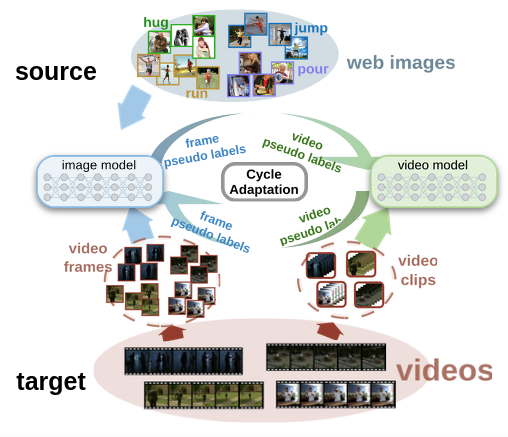
|
Wei Lin, Anna Kukleva, Kunyang Sun, Horst Possegger, Hilde Kuehne, Horst Bischof ECCV, 2022 paper / arxiv / code / video Unsupervised image-to-video domain adaptation. |
|
|
Wei Lin, Anna Kukleva, Kunyang Sun, Horst Possegger, Hilde Kuehne, Horst Bischof ECCV Workshop of Out Of Distribution Generalization in Computer Vision, 2022 paper / code / video |
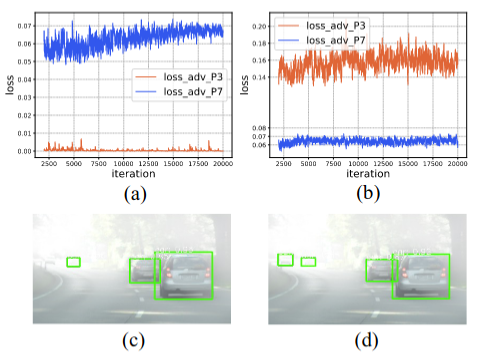
|
Kunyang Sun, Wei Lin, Haoqin Shi, Zhengming Zhang, Yongming Huang, Horst Bischof IEEE Robotics and Automation Letters (RA-L) 2023 paper / arxiv / code / video |
|
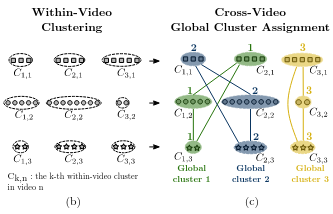
Wei Lin, Anna Kukleva, Horst Possegger, Hilde Kuehne, Horst Bischof Computer Vision Winter Workshop, 2023 arxiv / code / video |
|
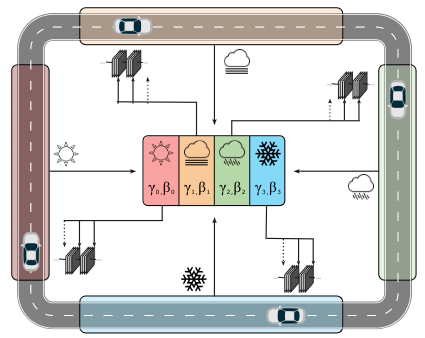
Stefan Leitner, Muhammad Jehanzeb Mirza, Wei Lin, Jakub Micorek, Marc Masana, Mateusz Kozinski, Horst Possegger, Horst Bischof Intelligent Vehicle Conference, 2023 arxiv / code / video |
|
|
|
|
|
|
|
|
|
template from Jon Barrion |